Ram Chillarege
IBM TJ Watson Research Center, Yorktown Heights, NY
Abstract:
This paper provides the motivation and overview of Orthogonal Defect Classification (ODC), a new technology for software process measurement and analysis. ODC provides a significant step forward in being able to understand the dynamics of software development by using classification of defects, so that they provide measurements. This breakthrough is being used at several IBM labs and is now supported by several processes, analyses and tools from the Thomas J. Watson Research Center.
Introduction to Software Defects
The notion of a defect in the software development and service industry tends to be different from the classical textbook definitions of fault, error and failure [Ed.92]. Essentially, it wraps several issues into one, sometimes obliterating the purported difference between error and fault, and at other times, identifying issues which by the formal definition of these terms may not fit into either. Accounts of what makes a software defect can often be challenged on the grounds of expected behavior of service, but the debate usually never ends since the causal train of events can often be perpetually pursued. Thus, in the realm of definition, there are philosophical differences between concept and practice, which should not appear as a surprise. The concepts get better with our advancement in engineering, while changes in practice, which exist in embodiments of tools and processes, are guided by time constants of changes in culture, which are often longer.
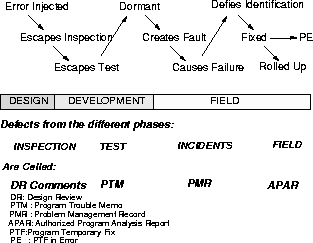
Figure 1: The Lifecycle of a Software Defect
To understand what a software defect is, it is helpful to have some idea of software development and its processes, or lack thereof. Although we do not need to get into the debate of what software development processes are and how many there are, it is reasonable to assume that there is usually some design, followed by development and field use. Figure 1 illustrates the lifecycle of software defects in the software development industry relative to such a process. It is a fallacy to believe that errors get injected in the beginning of the cycle and are removed through the rest of the development process. Errors occur all the way through this process. The fixing of these errors may occur sooner or later, deepening on knowledge of these errors and the ability to institute change into the product.
As a result of these errors, a change is necessary and that change is what I call a Defect. Tracking these changes is, in some quarters, reasonably common. However, there are development processes that are quite ill defined, where there may be no retrievable record of the change. Yet, for progress of the product, the change must have occurred and that change is the defect.
There is a subtlety in saying that the necessary change is the defect. This is because it could be the case that a change is necessary but was not executed. Someone may have forgotten about it, or there may have been no resource to fix it. It is still a defect, since it was deemed a necessary change.
Treating the necessary change as a defect ties the metaphysical concept of a fault, error, or failure to a physical event which makes this notion much more tractable. No matter what the development environment, the activity is specific and can become the anchor point from which other measurements can follow.
Defects during development
Software defects during the development process do not only occur due to program abnormal terminations or failed tests. In fact, the largest number of defects found during the lifecycle of a software product, often occur without the execution of the code. For example, a code inspection could typically yield 40% to 60% of the overall defects.
A software product usually begins with some set of requirements, either explicitly stated by a customer or identified through a vision of the market. Between the requirements and the availability of the product, there is design, code development and test. The words design, code and test do not automatically imply a pure waterfall process. On the other hand it is hard to imagine a successful product developed without requirements or code written without a design or tests conducted without code. A pure waterfall process tends to have these phases well identified and separated with documents that capture the essence of these phases, providing well defined handoffs between them. In more recent times, a small team with iterative development is commonly talked about, where the reliance of documentation and distinct handoffs are less emphasized. However, having some record of completion, milestones within a process are not only useful for project management but also internal for communication.
No matter what the exact implementation of the software development process, there is a distinct moment when a requirement, design or a piece of code is considered frozen. Its representation may be graphic, English text, video or audio tape. But the fact that there is agreement on an issue, the completion of an artifact in the development process, indicates a clear record of intent. Any further change to this record of intent is a change that is considered a defect. The tracking of a defect depends on how the process allows for a change to be understood, debated and handled. We are not arguing about whether or not there should be a moment that freezes the record of intent, for that would be a subject for a discussion on process existence. Nevertheless, it should suffice to say that if there were no moment when an intent of record is frozen - the process enters the domain of continuous change, which could yield an infinite completion time.
A process usually has several checks interspersed to ensure that the product being developed meets the record of intent. These checks could be reviews, inspections, informal tests, formal functional tests, stress tests, etc. Each of these verification efforts can identify deviations to the intent, which warrant change. Any thing that requires change is a defect. Thus, there are defects that arise from requirements inspection, design inspection (usually, a high level and a low level), a code inspection (of which there might be one or two), a unit test, a functional verification test and a system test. All these verification efforts can yield defects. Depending on what is counted you may find that the number of defects per thousand lines of code vary, from as high as 90 to as low as 10.
Following the final round of systems test within the organization, a product is often released to a subset of the customer base as a beta. The beta tells the customers to set their expectations appropriately while opening up a channel to listen on problems experienced with the product. When the vendor is satisfied about the products stability and performance (or forced to do so for business reasons), the product is announced and made generally available in the market. The product announcement is usually a key milestone in the history of the product, often accompanied by a celebration in the development shop.
Defects in the field
Software released into the field, is usually of a higher quality than when it is in system test or beta test. That reason is one of the objectives of the beta test. Software failure, due to defects, economically impacts the vendor one way or another. The vendor faces the service cost of fixing defects (which can be considerable) and can be adversely impacted by customer dissatisfaction with product quality.
One of the many reasons a customer calls in with a problem is usually due to a software fault. Problem calls originate due to several reasons that may not be due to a programming error. For instance, a customer problem may be due to difficulty in installation, misleading instructions, inadequate documentation etc. In each event, as far as the customer is concerned, it is a problem with the product. A subset of these problems would eventually warrant a change in the code - which in our terms would qualify for a software defect.
For the moment, let us focus on the subset of problems that are associated with defects. A customer call then reflects the failure due to a software fault. There could be several calls from different customers due to the same fault. The problem handling process in IBM allows for a symptomatic search on problems to investigate and identify the rediscovery of already known problems. If a rediscovery occurs and a fix is already available for that problem, it can be shipped to the customer right away. However, if the problem being experienced reflects a new fault hitherto unnoticed, it would require further investigation to provide a resolution.
When a new software fault is suspected through the problem management system, an authorized program analysis report (APAR) is opened to investigate it. The APAR starts the service process off to diagnosis, providing temporary relief when critical, and works toward developing the fix. The APAR thus becomes the vehicle to develop the fix, test the fix and then make the fix available through a world wide distribution network. The APAR thus straddles the service and the developmental process, since it starts off in the field, gets resolved and tested by developers and is integrated into future software releases in that product. The APAR is the king of software defects. It costs a lot of money, and is high up in the priority lists of customers, developers, and service people. No one wants to have APARs, neither the customer nor the developer, and it certainly gets a lot of attention.
At first approximation, an APAR would fit the definition of a software fault. However, on closer examination, it may be more than one fault that is being referred to. While the APAR certainly contains a fix to a fault, in actuality it may have others as they could be targeted to several releases in the field, and might also pre require other APARs. In an over simplified definition, it would pass for a fault. For the purpose of this paper, we can assume APAR and software fault to be synonymous.
It is interesting to note that APARs which are meant to fix problems, might also be the cause of new ones. This occurs when a bad fix is shipped out, i.e. the program temporary fix (PTF) is in Error - causing the infamous PE APAR. This can occur due to several reasons, the most dominant being that testing a fix under the customer environment is very hard. Thus, despite efforts to provide a good fix, the complexity of a customer environment is probably never replicated in the lab - resulting in inadequate test and another fault escaping into the field. PE APARs, though few and far between do exist and get the attention of the customer and the vendor. The figure on the defect lifecycle, thus, shows an origin of errors as fixes, which may sound like a circular statement, but nevertheless is a fact of life.
In-Process Measurement
Measurement on software defects has existed for a long time. In the industry, there is a substantial amount of effort in bean counting the defects and the accuracy and repeatability of this as an art form. The prediction of service costs using such bean counts can leave the casual scientist quite dumb founded. On the other hand, defect reports are not only used for bean counting, but often become the artifacts for postmortem studies on a release of software.
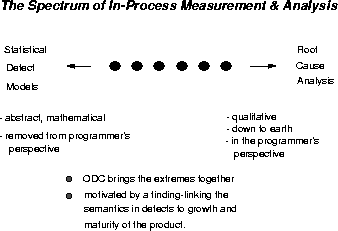
There is undoubtedly a broad spectrum in the use of defect information, and I illustrated this in figure 2. Two extremes are identified in the figure: One purely quantitative-i.e., numbers and the other purely qualitative - i.e., descriptive. As it happens, the two extremes are actually quite well defined and used. The middle part is where there is a large white space. Let us, for a moment, focus on the extremes.
The goal of statistical defect modeling, which includes what is commonly referred to as Software Reliability Growth, has been to predict the reliability of a software product. Typically, this may be measured in terms of the number of defects remaining in the field, the failure rate of the product, the short term defect detection rate, etc. [RB82, Goe85, MIO87]. Although this may provide a good report card, it often occurs so late in the development cycle that it is of little value to the developer. Ideally, a developer would like to get feedback during the process.
The goal of causal analysis is to identify the root cause of defects and execute actions so that the source of defects are eliminated. To do so, defects are analyzed, one at a time, by a team that is knowledgeable in the area. The analysis is qualitative and only limited by the range of human investigative capabilities. To sustain such pursuit and provide a focus for the activity, a process description has been found useful. At IBM, the Defect Prevention Process [MJHS90] and similar efforts elsewhere, have found causal analysis to be very effective in reducing the number of errors committed in a software project. The qualitative analysis provides feedback to developers that eventually improves both the quality and the productivity of the software organization [Hum89].
Defect Prevention can provide feedback to developers at any stage of their software development process. However, the resources required to administer this method are significant, although the rewards have proven to be well worth it. Moreover, given the qualitative nature of the analysis, the method does not lend itself well to measurement and quantitative analysis. Consequently, Defect Prevention, though not a part of the engineering process control model, could eventually work in conjunction with it.
The Gap - cause and effect relationship
Between the two extremes of the spectrum - quantitative statistical defect models and qualitative causal analysis, is a wide gap. This gap is characterized by a lack of good measurement methods that are meaningful to the developer and that can exploit good engineering methods. At one end, the traditional mathematical modeling efforts tend to step back from the details of the process and to approximate defect detection by statistical processes [LV73, Ohb84]. When calibrated, some of these methods are shown to be quite accurate. However, they do not provide timely feedback to the developers in terms of available process controls. At the other end, the causal analysis mechanism is qualitative and labor intensive; it can provide feedback on each individual defect. However, in a large development effort it is akin to studying the ocean floor with a microscope. It does not naturally evolve into abstractions and aggregations that can feed into engineering mechanisms to be used for overall process control.
It is not as though there is no work done between these two extremes, indeed there is a myriad of reported research and industry attempts to quantify the parameters of the software development process with ``metrics'' [IEE90b, IEE90a]. Many of these attempts are isolated and suffer from the absence of an overall methodology and a well defined framework for incrementally improving the state of the art. Some efforts have been more successful than others. For example, the relationship between the defects that occur during software development and the complexity of a software product, have been discussed in [BP84]. Such information, when compiled over the history of an organization [BR88], will be useful for planners and designers. There also is no one standard [IEE90b] classification system that is in vogue, although there have been efforts in that direction [IEE87].
In summary, although measurements have been extensively used in Software Engineering, it still remains a challenge to turn software development into a measurable and controllable process. Why is this so? Primarily because no process can be modeled as an observable and controllable system, unless explicit input-output or cause and effect relationships are established. Furthermore, such causes and effects should be easily measurable. It is inadequate to propose that a collection of measures be used to track a process, with the hope that some subset of these measures will actually explain the process. There should, at least, be a small subset which is carefully designed, based on a good understanding of the mechanisms within the process.
Looking at the history of the modeling literature in software, it is evident that little heed has been paid to the actual cause-effect mechanism, let alone investigations to establish them. At the other extreme, when cause-effect was recognized, though qualitatively, it was not abstracted to a level from which it could graduate to engineering models. Without that insight, and a rational basis, it is hard to argue that any one measurement scheme or model is better than another.
The birth of ODC
Orthogonal Defect Classification (ODC), is a technique that bridges the gap between statistical defect models and causal analysis. It brings a scientific approach to measurements in a difficult area that otherwise can easily become adhoc. It also provides a firm footing from which classes of models and analytical techniques can be systematically derived. The goal is to provide an in-process measurement paradigm for extracting key information from defects and enable the metering of cause-effect relationships. Specifically, the choice of a set of orthogonal classes, mapped over the space of development or verification, can help developers by providing feedback on the progress of their software development efforts. These data and their properties provide a framework for analysis methods that exploit traditional engineering methods of process control and feedback.
A key study established a relationship between the statistical methods of software reliability prediction and the underlying semantic content in the defects used for the prediction [CKC91]. The study demonstrated that the characteristics of the defects, identified by the type of change necessary to fix defects had a strong influence in the maturity of a software product being developed. This opened the doors to the possibility of measuring product maturity via extracting the semantic content from defects and measuring their change as the process evolves. ODC systematizes such measurements based on semantics and enforces the basic rules to turn that into a measurement.
Once the method to create a measurement system via classification is established, one can start developing measurements of different attributes in a process. For instance, "cause" and "effect" attributes can be categorized separately and the measurements then used to develop cause/effect models or relationships. Similarly, several attributes can be separately categorized yielding a large multi-dimensional space which can be used to increase understanding and help develop the physics of the process. This process is akin to a scientist who measures, weighs, stretches and stresses a physical object to be able to understand it's characteristics. Once the physics of that object is understood the engineers know how to model and control that object. The basics of how to gain a fundamental understanding of a software product and process, were never elegantly established. ODC provides the first steps to do so.
Key Concepts in ODC
ODC essentially means that we categorize a defect into classes that collectively point to the part of the process which needs attention, much like characterizing a point in a Cartesian system of orthogonal axes by its (x, y, z) coordinates. Although activities are broadly divided into design, code and test, in the software developemnt process, each organization can have its variations. It is also the case that the process stages in several instances may overlap while different releases may be developed in parallel. Process stages can be carried out by different people and sometimes different organizations. Therefore, for classification to be widely applicable, the classification scheme must have consistency between the stages. Without consistency it is almost impossible to look at trends across stages. Ideally, the classification should also be quite independent of the specifics of a product or organization. If the classification is both consistent across phases and independent of the product, it tends to be fairly process invariant and can eventually yield relationships and models that are very useful. Thus, a good measurement system which allows learning from experience and provides a means of communicating experiences between projects has at least three requirements:
- orthogonality,
- consistency across phases, and
- uniformity across products.
One of the pitfalls in classifying defects is that it is a human process, and is subject to the usual problems of human error, confusion, and a general distaste if the use of the data is not well understood. However, each of these concerns can be handled if the classification process is simple, with little room for confusion or possibility of mistakes, and if the data can be easily interpreted. If the number of classes is small, there is a greater chance that the human mind can accurately resolve between them. Having a small set to choose from makes classification easier and less error prone. When orthogonal, the choices should also be uniquely identified and easily classified.
Distribution change as a measurement
The concept of a classification system, that becomes a measurement is best illustrated with an example. The following example, brings several points together - namely semantic extraction, orthogonal classification and finally the necessary and sufficient conditions for ODC.
Figure 3 shows an example from the real world project, a major component of an operating systems product containing several tens of thousand lines of code. This figure has two charts; a growth curve on the top and a distribution on the bottom. The abscissa of the curve is time, indicated in days, spanning the testing portions of development. For the purpose of analysis it is partitioned into four periods, 0, 1, 2 and 3, each 200 days. The Growth curve on top is a plot of the cumulative number of defects against time. If the curve flattens out, it is goodness, since no further defects are uncovered. From the curve, it looks as though that the curve flattens out, but that is an artifact of the stopping of testing and that data beyond the release is not included! The total number of defects found through testing are around 800. Period 3, which was the last six to seven months, uncovered almost half the total defects. Period 3 was mostly systems test, when it desired that the product stabilize and not too many defects be found. However, it was clearly not the case in this case.
The reason we cite this example, is because it illustrates some of the difficulties encountered in development and the challenge it provides growth modelling. Somewhere during the middle of period 3, the defect find rates set off an alarm in the development organization. It was evident that more resource is needed for both testing and fixing the bugs, but the count of defects alone do not provide any insight into what might be a smart tactical solution. This is where the knowledge of what is contained in the defects can come to play.
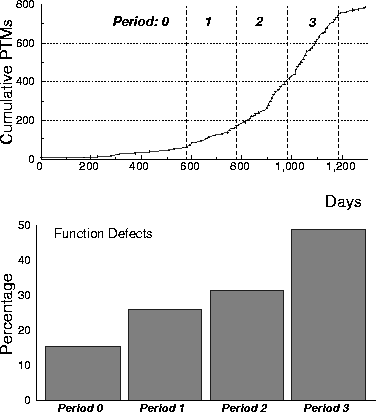
Figure 3: Growth Curve and Distribution of Function Defect Types
We chose this project to conduct a hind sight pilot, precisely due to the problems it encountered in development and the difficulty that classical growth modelling could not handle. We took defects from each of those periods and categorized them. We categorized them into a very carefully thought through set of attributes and values. One of the attributes is called the defect type, which we describe below. The defect type is merely the meaning of what is changed to fix the problem. The list of defect types used for this pilot study are: function, assignment+checking, interface, timing, documentation. The categories are simple, and are meant to reflect a set of programming tasks, yet general enough that they could apply to errors anywhere between design and the field. The categorization is really, what was intended by the person fixing the bug. A function bug is a capability that the program was supposed to provided either to the user or another program. Whereas, a checking defect is one where the program did not include a check of some condition or did so incorrectly. Inter module communication would be interface, while not holding a lock when one should would be related to timing. The categories are basic programming concepts or practices that are captured in the few distinct values. In actuality, the classification should provide the closed match to one of the identified values, thereby communicating the intent of the change.
With this background on classification of the defect type attribute, let us focus on the lower portion of figure 3. The bars, reflect the proportion of function defects in each of the periods, when categorized by the five possible selections above. It shows that in period zero between 10 and 20 percent of the defects were of type function. Period one was higher at 25 percent, and it continued to increase. Periods three and four show it going up from 30 percent to 50 percent. If one had a process where design precedes coding, and testing follows coding, the increasing proportion of function defects, together with the volume increase in defects, seems like it is growing backwards. Indeed, that is precisely the problem, recognized easily by the distribution of the defect types. In fact, if this data were available during the development process, it could not only clearly indicate the problems, but anticipate them, well before the sharp increase in defects in period three. Furthermore, it is also suggestive of the type of process correction that may be beneficial. The rise in functional defects is indicative of a design problems, and one of the options is to start a set of reviews using skills that best understand the design of the product. The post-morteum on the project told us that the project had slipped a few releases, key people had moved on, and it was resurrected with new people, while the requirements had continued to change.
What we are discussing here is the use of the semantic information that is buried in the defects, extracted through a simple, but powerful, classification scheme. If someone has the patience and attention span to read all 800 defects and understand their content the same conclusion may have been reached by recognizing the common element on functional deficiency or incorrectness with grew in intensity as the product advanced through testing. This is where it compares to root cause analysis, and is far more effective. The classification can become a measurement and based on an expectation, provide a measure of variance. The semantic nature of the classification, which is tied closely to the programming model provides guidance on what might be opportunities for process correction.
The classification scheme has to have certain properties so that it can indeed provide a measurement and these are called the necessary and sufficient conditions for ODC [CBC 92]. These become clearer when we discuss a more abstract model. Figure 4 shows four sets of histograms. Let us assume we have a very simple concept of process - there is a design phase, after which the code is written, unit tested, integrated with other code, function tested and then finally system tested to mimic a customer environment. Now, the classification system dictated that all the defects fell into four categories. The categories chosen are function, assignment, interface and timing. Now, thinking about the process model we had, we ask where should most of the function defects be found ? The answer, relative to the process is that the design phase (a design review, perhaps) is where we hope the bulk be found. Although, we do expect it to decrease as the process moved along, we expect less later.
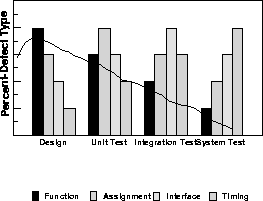
Figure: Change in the Defect Type Distribution with Phase
The figure, shows an expectation of the normalized defect type distributions by phase. Essentially, it says that for this kind of process we would like to see is that most of the function defects are found early and that should go down as the product goes through the process. It would also make sense if the timing and serialization problems only showed up towards the end because that's when the product is on the real hardware. Until then, the product is on a simulator or not the intended hardware. In between these two extremes, the process should weed out the assignment and interface defects. The unit-test probably has a peak in the assignment or one liner type defects and the interface defects tend to dominate when the new code is integrated with the rest and function tested.
By the process of the articulation above, we have in essence used the distribution of defects almost like an instrument to measure the progress of the product through the process. In fact, the distribution actually is indicative of how far the product has matured. So, if a product is supposedly in systems test, but the distribution of the defects tend to look similar to an earlier part of the process, and the volumes are not insignificant, then it clearly indicates a problem. In fact, it not only indicates the problem, but suggests what might be the possible reasons - via the offending defect types that are throwing off the distribution from the expected. As it happens, distribution changes are fare more sensitive and can be recognized easier than cumulative measurements, providing a useful tool to the developer. The feedback to a developer is available right after any two stages of development, providing rapid in-process feedback. Since the categories are in the language of a developer they are eminently more actionable.
Key to this technique, are the value set used for classification. This is governed by a necessary and sufficient condition - which essentially dictate what would be the right value set for a process. Establishing the right value set is an empirical process, since one is trying to compress the vast range of semantics into a few attribute-value pairs that capture the essence. We can describe where a chair is located in a room, by measuring off two adjacent walls and the ceiling, providing three orthogonal measurements in a three dimensional world. The question is can be place a measurement on a defect, by classifying the fix, such that a collection of them, can tell us via their distribution, where the product belonged in the process space. Essentially, the number of classes that are used to classify the defect should provide enough dimensionality such that it can resolve the process space we are interested in. Furthermore, since, the intent of the process is so that the product matures as it goes through it, the distribution of those defect types should change as the product moves through the process. Mathematically, the former is the sufficient condition and the latter the necessary condition. Since, choosing a classification scheme seems easy, a common error is to develop classification schemes, without much thought to how they are used later. In this case, it should be recognized that the key is to make a measurement out of them, and therefore substantial thought should be placed on the choice of the values of the defect type. They should as far as possible be distinct and independent. Furthermore, the value set should be applicable all through the process phases (consistency), else they cease to be a measurement. Lastly, they should be process independent, but generic the activity (in this case programming). Then, the controlled object can be the process, which when changed, does not impact the measurement system. Details of this are furthered explained in the ODC paper.
Summary
Orthogonal Defect Classification makes a fundamental improvement in the technology for in-process measurement for the software development processes. This opens up new opportunity for developing models, and techniques for fast feedback to the developer, addressing a key challenge that has been nagging the community for years.
At one end of the spectrum, research in defect modeling, that focused on reliability prediction, treats all defects as homogeneous. At the other end of the spectrum, causal analysis provides qualitative feedback on the process at a very small granularity. The middle ground did not develop systematic mechanisms for feedback due to the lack of fundamental cause-effect relationship extractable from the process. This work is built on some fundamental discoveries based on semantic extraction via classification that is carefully constructed to address the issue. Orthogonal Defect Classification provides a basic capability to extract signatures from defects and infer the health of the development process. The classification is to be based on what was known about the defect such as its defect type or trigger and not on opinion such as where it should have been found. The choice of the classes in an attribute should satisfy the stated necessity and sufficient conditions so that they eventually point to the part of the process that requires attention.
The design of the defect type attribute measures the progress of a product through the process. Defect type identifies what is corrected and can be associated with the different stages of the process. Thus, a set of defects from different stages in the process, classified according to an orthogonal set of attributes, should bear the signature of this stage in its distribution. Moreover, changes in the distribution can meter the progress of the product through the process. The departure from the expected distribution alerts us by pointing to the stage of the process that requires attention. Thus, the defect type provides feedback on the development process.
The design of the defect trigger attribute (not covered in this short overview paper, but available in the original reference) provides a measure of the effectiveness of a verification stage. Defect triggers capture the circumstance that allowed the defect to surface. The information that yields the trigger measures aspects of completeness of a verification stage. The verification stages could be the testing of code or the inspection and review of a design. These data can eventually provide feedback on the verification process. Taken together with the defect type, the cross-product of defect type and trigger provides information that can estimate the effectiveness of the process.
Our experience with ODC, indicates that it can provide fast feedback to developers. Currently, two stage data is used for trend analysis to yield feedback. It is envisioned that as pilots evolve, the measurements can yield calibration.
Developers find this a useful method, giving them insight they did not have before. It also provides a reasonable level of quantification to help make better management decisions to significantly impact cost and opportunity.
References
V. R. Basili and B. T. Perricone. Software Errors and Complexity: An Empirical Investigation. Communications of the ACM, 27(1), 1984.
V. R. Basili and H. D. Rombach. The TAME Project: Towards Improvement Oriented Software Environments. IEEE Transactions on Software Engineering, 14(6):758-773, June 1988.
R. Chillarege, I. Bhandari, J. Chaar, M. Halliday, D. Moebus, B. Ray, and M. Wong. Orthogonal defect classification - a concept for in-process measurement. IEEE Transactions on Software Engineering, 18(11):943-956, Nov 1992.
R. Chillarege, W-L Kao, and R. G. Condit. Defect Type and its Impact on the Growth Curve. In Proceedings of The 13th International Conference on Software Engineering, 1991.
J. Laprie Ed. Dependability: Basic Concepts and Terminology, 1992.
A. L. Goel. Software Reliability Models: Assumptions, Limitations, and Applicability. IEEE Transactions on Software Engineering, 11(12):1411-1423, 1985.
W. S. Humphrey. Managing the Software Process. Addison-Wesley Publishing Company, 1989.
IEEE Standards. A Standard Classification of Software Errors, Faults and Failures. Technical Committee on Software Engineering, Standard P-1044/D3 - Unapproved Draft, December 1987.
IEEE Software. Theme Articles: Metrics. IEEE Software, 7(2), March 1990.
IEEE Standards. Standard for Software Quality Metrics Methodology. Software Engineering Standards Subcommittee, Standard P-1061/D21 - Unapproved Draft, April 1990.
B. Littlewood and J. L. Verrall. A Bayesian Reliability Growth Model for Computer Software. Journal of Royal Statistical Society, 22(3):332-346, 1973.
J. D. Musa, A. Iannino, and K. Okumoto. Software Reliability - Measurement, Prediction, Application. McGraw-Hill Book Company, 1987.
R. Mays, C. Jones, G. Holloway, and D. Studinski. Experiences with Defect Prevention. IBM Systems Journal, 29(1), 1990.
M. Ohba. Software Reliability Analysis Models. IBM Journal of Research and Development, 28(4):428-443, 1984.
C. V. Ramamoorthy and F. B. Bastani. Software Reliability - Status and Perspectives. IEEE Transactions on Software Engineering, 8(4):354-371, 1982.