Ram Chillarege and Kathryn A. Bassin IBM Thomas J. Watson Research Center, 1995
- Defines triggers for the three primary verification activities: software review and inspection, function test and system test.
- Provides three trigger distributions as a function of time, attributable to escapes to the field from each of the verification activities: review, function test and system test.
- Illustrates that each trigger peaks at a different time from date of release. This is a key finding with significant implications in several aspects of software dependability and software engineering.
Dependable Computing for Critical Applications 5, Urbana-Champaign, 1995, Dependable Computing and Fault-Tolerant Systems Vol. 10, IEEE Computer Society
Introduction
One of the key aspects of failure generation is the activation process by which a software fault causes an error and then results in a failure. This has broadly been attributed to usage patterns or environmental conditions that are prevalent under different circumstances. However, there has been very little work that tears apart the activation process in order to provide a much greater understanding of the mechanisms that cause faults to surface. The seemingly random process of failure occurrence is relatively well understood when dealing with hardware and technology where faults have comparatively short latencies. In contrast, software fault latencies are quite large, and are much less understood. Thus, the triggering mechanisms that terminate the fault latency hold the key to a large part of this understanding.
This paper explores this opportunity and provides some understanding of the triggering process. Specifically, the paper provides the distributions of the triggers that caused faults to be activated resulting in failures. To do so, we have studied the faults from an operating system product, over a period of two years after release into the field. In addition to providing the distribution of the triggers, these distributions are studied as to how they change as a function of time. The change as a function of time is the first ever reported and illustrates the dynamics of the customer environment.
The value of this study is that it brings into active discussion what we believe is one of the key aspects in the failure generation process, namely, triggers. Triggers influence several issues, some academic and some practical. They capture the mix of the customer environment and measure the aggregate operational profile [MIO87]. Thus, it makes for excellent input towards estimation and projection of software reliability. On the other hand, triggers quantify one of the critical contributors that varies the acceleration in a fault injection experiment. For the successful development of the fault injection methodologies [CB89], [Ae90], one needs to understand what makes faults generate errors and result in failures. Triggers are the factors that makes it happen. Thus, understanding and quantifying triggers and their characteristics provides the guidance for research, modelling and importantly, driving the design of fault injection experiments.
To conduct this study, we have chosen an operating system product with several million lines of code. The product enjoys a large customer base, with significant install growth within a short period of time after being made available. It is a system-wide product exploited in a large environment. Customers have full support for all types of software problems, with software fixes dispatched for all known faults. The product is renowned for its dependability. Data from field failures spanning a two-year period in the field is used to identify triggers and drive the analysis.
To help communicate the results of this paper, we begin with a brief discussion of what triggers are. Although triggers have been introduced in our earlier work, given that it is a new concept, the paper benefits with some explanation and clarification. This is followed by a set of definitions on triggers, which are currently not available in our publications. The data from this study is then presented with the discussions.
We believe that this article should be of interest to a fairly wide audience in the dependable computing industry. Specifically, it would interest the fault injection community given that the trigger is a key parameter, which controls the acceleration of failure in a system. In addition, the activation mechanism is particularly relevant as to when and where to inject faults. This is usually a difficult question in software given that the sample space is large, both in time and space. Since the trigger is the catalyst for failure, it provides the additional guidance on prescribing the environmental conditions under which faults need to be injected to emulate real world conditions. The work should also be of interest to reliability modelling and prediction, since the trigger is one of the dominant parameters that can be related to the probability with which faults turn into failure in the field. Finally, once we have an understanding of the catalyst, it motivates the designers of fault tolerance to conceive of methods to detect and subvert failure in the field. Thus, we believe that this paper and its results have a far-reaching relevance to the dependable computing community at large.
Software Triggers and ODC
Software faults are dormant by nature. This is particularly true when considering faults that cause failures once a software product is released in the field. Faults which surface as failures for the first time after a product is released often have been dormant throughout the period of development, which can range from a few months to a few years. Furthermore, these faults do not necessarily surface in the first few months of field exposure, but often remain dormant for several years.
What is it that works as a facilitator, activating dormant software faults to result in failures ? That catalyst is what we call the trigger. We are not trying to identify the specific sensitization that is necessary for each unique fault to be exercised. We are instead identifying the broad environmental conditions or activites which work as catalysts assisting faults to surface as failures. In an abstract sense, these are operators on the set of faults to map them into failures. Figure 1 illustrates different triggers that force a fault to a failure.

The concept of the trigger is quite new. To put it in perspective, let us for a moment digress and discuss the more commonly known attributes of failures. This will help us differentiate what triggers are and clarify any potential confusion. Some of the more commonly discussed attributes of failures are their failure modes and characteristics such as symptom, impact and severity. The symptom, a visible attribute, is the characteristic displayed as a result of the failure and the net affect on the customer. For instance, the symptom attributes reported in the IBM service process have a value set such as: hang, wait, loop, incorrect-output, message, and abnormal termination (abend). The fault injection experiments also use a similar attribute (often called failure or failure mode) with a value set such as: no error, checksum, program exit, timeout, crash, reboot, hang etc. [KKA95], [KIT93], [HSSS93]. The impact is an attribute that characterizes the magnitude of outage caused or severity, such as: timing, crash, omission, abort fail, lucky, and pass, [SHSS93].
At first glance, it is not uncommon to confuse the symptom with the trigger. However, they are very different and orthogonal to each other. In simple terms, the trigger is a condition that activated a fault to precipitate a reaction or series of reactions, resulting in a failure. The symptom is a sign or indication that something has occurred. In other words, the trigger refers to the environment or condition that helps force a fault to surface as a failure. A symptom describes the indicators that a failure has occurred, such as a message, an abend, a softwait etc. Thus, a single trigger could precipitate a failure with any of the above symptoms or severities, and conversely a symptom or severity could be associated with a variety of trigger mechanisms. In Figure 1 the failure is shown as a single state. However, when characterized with several failure modes or symptoms, that state could be split into several. The triggers  would each contribute to the different failure states identified. In this paper, we have focused on triggers and do not embark on the mappings between different triggers and the symptoms of different failures. However, these mappings have been studied and will be discussed in a separate article.
would each contribute to the different failure states identified. In this paper, we have focused on triggers and do not embark on the mappings between different triggers and the symptoms of different failures. However, these mappings have been studied and will be discussed in a separate article.
The concept of the software trigger was introduced in [SC91] where it was applied to failure analysis from defects in the MVS operating system, with the intention of guiding fault-injection. Since then, several advancements were made to the notion of triggers, most notably when orthogonal defect classification (ODC) was developed as a measurement technology [CBC92]. Later the concept of the trigger was extended to the design phase in the software development paradigm [CHBC93].
There are specific requirements for a set of triggers to be considered part of orthogonal defect classification, and a process to establish them. We do not attempt to completely explain the concepts here and the details of the necessary and sufficient conditions are best found in [CBC92]. However, to briefly summarize the ideas, it requires that the distribution of an attribute (such as trigger) changes as a function of the activity (process phase or time), to characterize the process. In addition, the set of triggers should form a spanning set over the process space for completeness. Changes in the distribution as a function of activity then become the instrument, yielding signatures which characterizes the product through the process. This is when the trigger value set is elevated from a mere classification system into a measurement on the process and qualifies to be called ODC. In this case, the triggers become a measurement on the verification process. The value set has to be experimentally verified to satisfy the stated N+S conditions. Unfortunately, there is no short cut to figure out the right value set. It takes several years of systematic data collection, experimentation and experience with test pilots to establish them. However, once established and calibrated, they are easy to roll out and productionize. We have the benefit of having executed ODC in around 50 projects across IBM providing the base to understand and establish these patterns.
Triggers form a vital measurement and have several uses. Since it conforms to ODC, it can be used in conjunction with other ODC attributes such as defect-type, which measures the progress of a product along the development process axis to yield effectiveness measures. This cross-product of defect-type and trigger can provide very fast feedback within one stage data [CBC92].
So far, only preliminary aggregate trigger distributions have been published in some of our earlier papers. However, an in-depth analysis of triggers and how the distributions emerge as a function of time after product release have not been illustrated. This paper focuses on just one specific aspect of ODC, namely triggers. Furthermore, the focus is directed towards faults that manifest in failures during the operating life of the product. This is chosen primarily to pay attention to the needs of the dependability community. Since software became a dominant cause of system outage [Gra90] a clearer understanding of failure mechanisms was critically needed. An analysis of triggers provides a significant part of the needed insight.
Software Triggers and ODC
Software faults are dormant by nature. This is particularly true when considering faults that cause failures once a software product is released in the field. Faults which surface as failures for the first time after a product is released often have been dormant throughout the period of development, which can range from a few months to a few years. Furthermore, these faults do not necessarily surface in the first few months of field exposure, but often remain dormant for several years.
What is it that works as a facilitator, activating dormant software faults to result in failures ? That catalyst is what we call the trigger. We are not trying to identify the specific sensitization that is necessary for each unique fault to be exercised. We are instead identifying the broad environmental conditions or activites which work as catalysts assisting faults to surface as failures. In an abstract sense, these are operators on the set of faults to map them into failures. Figure 1 illustrates different triggers that force a fault to a failure.
The concept of the trigger is quite new. To put it in perspective, let us for a moment digress and discuss the more commonly known attributes of failures. This will help us differentiate what triggers are and clarify any potential confusion. Some of the more commonly discussed attributes of failures are their failure modes and characteristics such as symptom, impact and severity. The symptom, a visible attribute, is the characteristic displayed as a result of the failure and the net affect on the customer. For instance, the symptom attributes reported in the IBM service process have a value set such as: hang, wait, loop, incorrect-output, message, and abnormal termination (abend). The fault injection experiments also use a similar attribute (often called failure or failure mode) with a value set such as: no error, checksum, program exit, timeout, crash, reboot, hang etc. [KKA95], [KIT93], [HSSS93]. The impact is an attribute that characterizes the magnitude of outage caused or severity, such as: timing, crash, omission, abort fail, lucky, and pass, [SHSS93].
At first glance, it is not uncommon to confuse the symptom with the trigger. However, they are very different and orthogonal to each other. In simple terms, the trigger is a condition that activated a fault to precipitate a reaction or series of reactions, resulting in a failure. The symptom is a sign or indication that something has occurred. In other words, the trigger refers to the environment or condition that helps force a fault to surface as a failure. A symptom describes the indicators that a failure has occurred, such as a message, an abend, a softwait etc. Thus, a single trigger could precipitate a failure with any of the above symptoms or severities, and conversely a symptom or severity could be associated with a variety of trigger mechanisms. In Figure 1 the failure is shown as a single state. However, when characterized with several failure modes or symptoms, that state could be split into several. The triggers would each contribute to the different failure states identified. In this paper, we have focused on triggers and do not embark on the mappings between different triggers and the symptoms of different failures. However, these mappings have been studied and will be discussed in a separate article.
The concept of the software trigger was introduced in [SC91] where it was applied to failure analysis from defects in the MVS operating system, with the intention of guiding fault-injection. Since then, several advancements were made to the notion of triggers, most notably when orthogonal defect classification (ODC) was developed as a measurement technology [CBC92]. Later the concept of the trigger was extended to the design phase in the software development paradigm [CHBC93].
There are specific requirements for a set of triggers to be considered part of orthogonal defect classification, and a process to establish them. We do not attempt to completely explain the concepts here and the details of the necessary and sufficient conditions are best found in [CBC92]. However, to briefly summarize the ideas, it requires that the distribution of an attribute (such as trigger) changes as a function of the activity (process phase or time), to characterize the process. In addition, the set of triggers should form a spanning set over the process space for completeness. Changes in the distribution as a function of activity then become the instrument, yielding signatures which characterizes the product through the process. This is when the trigger value set is elevated from a mere classification system into a measurement on the process and qualifies to be called ODC. In this case, the triggers become a measurement on the verification process. The value set has to be experimentally verified to satisfy the stated N+S conditions. Unfortunately, there is no short cut to figure out the right value set. It takes several years of systematic data collection, experimentation and experience with test pilots to establish them. However, once established and calibrated, they are easy to roll out and productionize. We have the benefit of having executed ODC in around 50 projects across IBM providing the base to understand and establish these patterns.
Triggers form a vital measurement and have several uses. Since it conforms to ODC, it can be used in conjunction with other ODC attributes such as defect-type, which measures the progress of a product along the development process axis to yield effectiveness measures. This cross-product of defect-type and trigger can provide very fast feedback within one stage data [CBC92].
So far, only preliminary aggregate trigger distributions have been published in some of our earlier papers. However, an in-depth analysis of triggers and how the distributions emerge as a function of time after product release have not been illustrated. This paper focuses on just one specific aspect of ODC, namely triggers. Furthermore, the focus is directed towards faults that manifest in failures during the operating life of the product. This is chosen primarily to pay attention to the needs of the dependability community. Since software became a dominant cause of system outage [Gra90] a clearer understanding of failure mechanisms was critically needed. An analysis of triggers provides a significant part of the needed insight.
Trigger Definitions
There are three classes of triggers associated with the three most common activities of verification. Since each of the activities tend to be very different from one another, they call for different sets of triggers. System test, function test and review/inspection form the three substantially distinct verification activities. The distinction arises from how they attempt to detect faults. In one form or another they all attempt to emulate customer usage. However, the level of observability of the code and function vary and the issues addressed are driven by different motivations. Thus, triggers for each of these classes of verification are unique. In the following subsections we define each of these verification classes and their triggers.
System Test Triggers
System test activities deal with system wide and cross-system issues, including hardware and software environment implications as well as cyclic and sometimes demanding workload volumes.
Recovery
corresponds with validating the product's ability to recover from error conditions. Customers prefer that failures never occur. If a fault does become a failure, however, it is highly desirable that the system or product is able to recover from the defect and carry on with as little impact to the customer as possible. One of the tasks of system test is to inject faults in order to evaluate the system or product's ability to recover gracefully.
Start (initialize) and Restart
can be related to Recovery, since they are associated with starting or restarting a system following an earlier shutdown or complete system or product failure. It may have appeared that the system or product recovered successfully from a failure, only to find later that critical information was lost or control areas overlaid.
Workload Volume/Stress
is exemplified by the ability (or inability) of a system or product to operate effectively and without failure at or near a resource limit. The mechanisms which system test uses to emulate to these scenarios could include heavy network traffic, many users, or a large number of system transactions, among others.
Hardware Configuration and Software Configuration
are triggers which cause failures to surface that are related to unusual or unanticipated configurations. The industry is volatile with regard to software and hardware products. The need for these products to interact and interface successfully is of utmost concern. Attempting to ensure this is an important system test activity.
Normal Mode
is a trigger which says, in effect, that no special conditions needed to exist in order for the failure to surface. There is strong evidence to suggest that the real trigger is, in fact, associated with an earlier activity. When classifying field reported failures, if the environment description sounded like 'Normal Mode' there would almost always clearly be an associated inspection Trigger. Aside from the broader implications, there is one very specific application of this phenomenon. A product, against which a high percentage of defects classified as Normal Mode surfaces during system test, would most certainly benefit from revisiting earlier activities before it is released to the public.
Review and Inspection Triggers
Triggers associated with design review and code inspection activities during development deal primarily with requirements and design. The focus of design review is on ensuring that the functional requirements for the product are complete, understood, and incorporated into the design. Code inspection is undertaken in order to ensure that the design has been interpreted accurately, and coded correctly.
Backward Compatibility
is an area of great concern. As customers migrate to the most recent products, they take with them a body of applications that were used successfully in the previous environment. Customers want these applications to run successfully in the new environment with minimal, if any, required changes.
Lateral Compatability
addresses another critical requirement of customers, that is, that products are able to function with other products of the same generation. Lateral compatibility becomes an increasing challenge throughout later periods of a product's life cycle as more and more products are introduced. Thus, a particular aspect of this area is anticipating accurately the interface requirements of products which do not yet exist.
Design Conformance
related faults are targeted by reviewers or inspectors who attempt to ensure that the interpretation of requirements, structure, or logic matches the corresponding document. These triggers are manifested in the field by customer reported problems which describe situations where the product did not function in a manner that meets the customer's requirements or expectations.
Concurrency
is one of three triggers which are associated with the importance of understanding the details beneath the overall design. This trigger applies to simultaneous use of the same resources, and has implications of security, locking mechanisms, and sometimes performance. For customers, these often appear as long, indefinite waits for a command or function to complete.
Logic Flow
is the second of these triggers, and relates to those occasions when the operational semantics are in question. From a customer viewpoint, the result of a fault in this area is often manifested when a command or program completes, but the returned information is inconsistent or incorrect, but there are many other possibilities as well.
Side Effects
is the third trigger which is best tackled by an experienced developer, well versed in not only the details of the product under development, but also aware of potential impacts on another function or product. When these faults surface in the field, they are characterized by seemingly unrelated symptoms, often difficult to diagnose.
Documentation
is a trigger associated with both the internals information, such as prologues and code comments, and externals such as user guides and installation manuals. Customers rely heavily on accompanying documentation, whether hard copy or on-line, for information about the abilities of the function or product, how to invoke the capabilities, and the results which can be expected. The extent to which the logic flow and interfaces are documented in the code has a significant influence on the prevention of future faults, as well as impacting the degree to which a reported fault can be diagnosed and corrected quickly.
Rare Situation
triggers are also best tackled by experienced developers. They are, by definition, unusual sets of circumstances, for the majority of customers. It is possible, however, that a rare situation for many is a common problem for a particular set of customers. Thus, understanding and interpreting these triggers could become an important element in accommodating particular environments.
Function Test Triggers
There are several terms used to describe the testing of the functional aspect of a product. Depending on the size and scope of the project, any or all could be applied under the heading of function test. Unit test, for example, is an effort to validate the ability of the code written to execute successfully, independently from other influences such as interfaces with other products or functions. Function test takes a broader view, ensuring not only that the function executes successfully, but that interfaces are handled correctly, and that the function provides expected results. Component test is a term applicable to a large product which consists of multiple elements (components). This additional 'function test' ensures that all of the functions within a component perform satisfactorily, and the components of a product interface correctly with each other.
Each of these types of test effort would have a characteristic trigger signature, for example, the triggers most often associated with Unit test would be those at the simple end of the scale, while those associated with Component test would be predominantly more complex. One consideration is that, in general, the more complex the test scenario, the greater it's ability to test not only the code, but the underlying design. Whether these various approaches are appropriate in all cases, or are combined in an organization, is irrelevant to the topic at hand, however, and therefore we have chosen to combine all of these activities under one heading, 'function test'.
Test Coverage
refers to the use of an obvious test case of an external function. From a customer viewpoint, this would correspond to entering a single command, with a single set of parameter values.
Test Sequencing
is another relatively simple scenario, which examines the sequential effect of executing more than one body of code. This trigger reflects a customer scenario in which a simple series of commands is entered, such as 'create file', 'open file', 'close file'.
Test Interaction
begins to introduce more complex conditions, with multiple commands and multiple parameters interacting with each other. Customer environments in which databases are shared among multiple end users, and each command is dependent to a large degree on the successful execution, stored information, and interfaces of other functions, will often result in the surfacing of these types of faults.
Test Variation
is another trigger which requires more complex scenarios. It involves an attempt to exercise a single function in many different ways by entering a combination of parameters and values, sometimes invalid ones. These faults often show up as situations in which the customer inadvertently enters a parameter incorrectly, and instead of handling the situation and returning a meaningful message to the customer, the program abends.
Simple Path and Combination Path
are two additional triggers associated with function test which require some knowledge of how the code is designed and executed, as well as the logic flow. While this is not purely an external viewpoint, many customers apply some knowledge of these internals to the task of using the function in ways which are of particular interest to them, sometimes in an unexpected manner. The distinction between the two triggers is one of complexity: Simple path is a straightforward attempt to force specific branches to be executed, while complex path attempts to exercise these branches under varying conditions.
Results and Discussion
We present trigger data from an operating systems product that has been studied in the field for a duration of two years. The data is used to extract triggers by reading the defects and manually classifying them into the different possible triggers. Usually the fault reports contain a sufficient description of the situation under which the failure was caused, thereby providing us the input to identify the trigger. When information involving customer reported failures is captured in IBM, the reports are written in such a way as to make the translation to triggers a relatively simple task. The intent of the failure report text is to describe key elements of the failing scenario in order to facilitate two activities. First, to enable the failure to be recreated in order to isolate and diagnose the fault, and second, to enable the failure record to be easily found in the event the failure is reported by another customer.
While associating these customer reported failures with related development activities is not of primary importance to customers, it is an extremely valuable analysis from a defect prevention and removal viewpoint. Thus, extracting the 'real life' trigger from the manner in which the customer exercises the code from an external viewpoint is fairly straightforward.
Note that each of the triggers may belong to any one of the three groupings, review and inspection triggers, function test triggers or system test triggers. Once having established the trigger that occurred in the field, the grouping allows us to identify the most likely part of the process where the faults escaped detection.
There are two major kinds of results that we report in this section. The first has to do with the nature and characteristics of triggers. The second has to do with very specific inferences from the trigger distributions that we have found with this product. The first group of results address general issues, on how triggers are manifested in the field and how they could be used to improve predictions, diagnosis, process changes, and fault injection. The second kind of result has to do with the specific issue involving the operating system chosen and provides very practical insight on strategies that could be adopted given the nature of the data that we discuss.
General Issues
The triggers were grouped according to the three activities, namely, review/inspection, function test, and system test triggers. In all, there were 2,770 faults that were classified and Figure 2 shows the distribution of the three different classes of triggers. Notice that only 720 would be attributed to what we may refer to as system test triggers. The others have been classified into triggers associated with either review/inspection or function test. A paradigm that is cherished by many is that the only escapes into the field, one hopes, occur from system test, since it is the last phase in the process. The data reveals that to be only around 25%. 75% of the faults escape from parts of the process that are associated with elements of design or the standardized function and component test. The advantage of looking at faults by trigger is that one can identify very specific actions to target the categories of faults that come under a trigger.

Figure 2: Attributing activities via Triggers
Figures 3, 4, 5 show distributions of each of these groups of triggers as a function of time. The way the charts are drawn one can see that the different triggers tend to peak at different times after product release. This is, in fact, one of the first results ever demonstrated showing that the operational profile aggregated on a product is very much a function of the time after release. Therefore, early in the life of a product there are a different set of triggers that cause failures whereas later in the life of a product, again the mix of triggers that cause failures change. This is true for each of the three groupings of triggers. Once we notice the ones that are peaking, such as documentation or concurrency in the case of review/inspection triggers it is understandable that those would peak early and not later, as is the case with lateral compatibility or logic flow. However, this level of insight has never before been provided.
The fact that each trigger has a different distribution as a function of time is a very key observation. This knowledge opens the doors to a variety of techniques as well as process changes to deal with the issue. There are tactical methods by which we can control the early life fall-out in the field by going after the triggers that tend to dominate the early fault discovery. Usually after about three months in the field, there is a possibility of providing a service pact to the field in order to cover known faults and potentially avoid future faults. Knowing that certain triggers actually peak later in the product life gives us a tactical opportunity to focus on certain kinds of testings ahead of other kinds of tests. There is usually much debate about the reason why faults escaped into the field. It is often argued that testing is never complete and that escapes into the field are either dominated by design issues or non-design issues. This kind of discussion is usually based on opinions of people rather than quantified evidence as to why a particular fault escaped the development process. The technique we use here is to first identify the trigger, offering a crisp articulation of the reason why a fault was not caught. Then, depending on the trigger attribute, we are able to discern the part of the process that allowed an escape. For instance, if the trigger was a variation in the function that was not exercised during development but is now exercised in the field, it would be identified as a test variation trigger, belonging in the class of component or function test triggers. This enables us to make the assertion that this fault was really an escape of component function test and is, we believe, a much more objective assessment of the escape. Thus, for analysis such as we showed in Figure 2 which provides strong evidence of the different potential areas of escape we believe that identifying the trigger first and then attributing a potential escape is a superior mechanism to follow.
Specific Issues
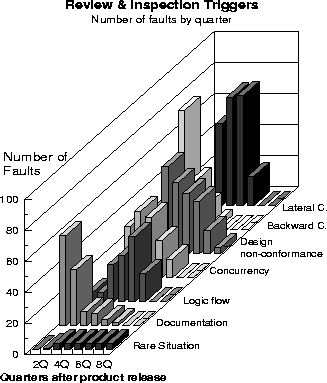
Figure 3: Review, Inspection Trigger Distribution

Figure 4: Function Test Trigger Distribution

Figure 5: System Test Trigger Distribution
In this subsection, we will look at the trigger profiles in Figures 3, 4, 5 and discuss the trends we notice.
First, let us look at Figure 3 which shows the inspection class of triggers. These triggers are usually issues that can be attributed to design. The relatively flat distribution of 'design non-conformance' triggers over the first year and a half suggests that the customers are continuously poking and prodding the functional aspects of the product. Thus, relative to the other triggers, there is no sharp peak. Documentation and backward compatibility failures, if they occur, are likely to be uncovered very quickly. In contrast, lateral compatibility failures don't peak until almost a year later. The implication is that the product is able to handle environments which were available when it was introduced, but as the customer begins to install new products, which probably were not available when the product was being tested, faults begin to surface.
Second, let us focus on the 'function test' triggers as shown in Figure 4. Customers who are exploiting the product based on some knowledge of internals, tend to do so in the first year. This is inferred because both simple path and complex path triggers have little or no activity in the second year, and are mostly concentrated in the first year. However, note that between the two, simple path hits early, followed by complex path after two quarters.
Both test coverage and test variation triggers show a long, relatively flat distribution over the two year period. The probability of a test coverage fault surfacing is much higher in the first year, while test variation faults are much more likely to surface in the second year. The specific reasons for this phenomenon may be related to complexity, new software, new hardware, or the fact that the relatively simple problems are uncovered first before the customer becomes more adventurous. This is potentially an interesting avenue to explore, but is beyond the scope of this paper.
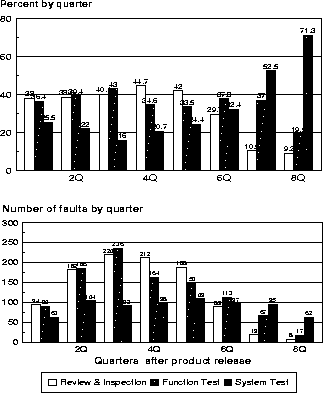
Figure 6: Fault Rate by Quarter
Finally, the system test trigger distributions, are shown in Figure 5. This shows perhaps the strongest story in terms of when one might expect specific faults to surface. The fact that hardware configuration failures are most likely to occur well into the second year, suggests that the bulk of hardware upgrades occur in that time frame. In contrast, software products appear to be upgraded very quickly, and frequently. The evidence that workload/stress failures do not show up until the second year indicates that customers probably don't push their system to it's limits until then. Startup/restart failures, if they occur, are likely to be uncovered immediately. The product's ability to recover gracefully from errors will be taxed throughout it's life.
In addition to the implications derived from examining when various triggers cause faults to surface in the field, another significant and unique aspect of a product relates to the volumes of each defect trigger reported by customers. These volumes appear to be influenced by both customer usage of the product and, more significantly, the relative success of fault removal and prevention during the development cycle relative to individual triggers.
Figure 6 shows the distribution over time of the faults associated with each of the three verification activities, by quarter. These are shown both by the volume of faults and the percent contribution during each quarter, to help look at the trends and the changes in the mix. The fact that the volume of review and inspect escapes and function test escapes far exceeds the volume of system test escapes has already been pointed out. It is interesting to note that, for this product at least, the distribution over time of the volume of system test escapes is relatively flat over time, while the volume of review and inspect escapes peak at about a year and then decreases rapidly. Thus, as time progresses, the percent of faults that are found primarily due to system test triggers increases, as should be expected. This view of the data enables us to form a prediction of field activity over time, while the views reflected in Figures 3, 4 and 5 offer a tremendous opportunity to target pre-release activities to effectively prevent or remove characteristic faults. The next progression is to quantify the expected benefit of actions identified to target specific triggers, evaluate the actual results in process, and adjust the field projection to accommodate these factors. Further expansion of this concept is, again, beyond the scope of this paper, but offers exciting potential for future investigation.
Summary
This paper provides insights into the activation process of software failures, a topic that has very little work to date. The study is based on an operating system product's faults, collected over a period of two-years from general availability for two releases. The paper describes what triggers are, and provides definitions of triggers, as they have been delivered as a part of ODC Release 3.1. for several years. It provides distributions of the triggers from three groups: review/inspection, function test and system test.
Some of the key results shown and discussed are the distribution of the triggers, by each trigger, within each of the groupings. One of the interesting observations, that is valuable to the dependability and software engineering community is that individual triggers peak at different times over the two year period in the field. This is reflective of the different stresses that appear on a product from a customer usage standpoint. The level of resolution provided by the analysis of triggers, enables an understanding of the exact nature of the field forces. These findings are of particular value in experimental design (fault injection), modelling, and a variety of tactical approaches to manage testing or the dependability of products.
This paper breaks new ground in the area of software failure and dependability, which has clearly become the key driving force in the industry. These results should be of interest to the entire community.
References
J. Arlat and et.al. Fault injection for dependability validation, a methodology an some applications. IEEE Transactions on Software Engineering, 16, Feb 1990.
R. Chillarege and N. Bowen. Understanding Large System failures - a fault injection experiment. Digest of Papers The 19th International Symposium on Fault Tolerant Computing, June 1989.
R. Chillarege, I. Bhandari, J. Chaar, M. Halliday, D. Moebus, B. Ray, and M. Wong. Orthogonal defect classification - a concept for in-process measurement. IEEE Transactions on Software Engineering, 18(11):943-956, Nov 1992.
J. Chaar, M. Halliday, I. Bhandari, and R. Chillarege. In-Process Evaluation for Software Inspection and Test. IEEE Transactions on Software Engineering, 19(11), Nov 1993.
J. Gray. A Census of Tandem System Availability between 1985 and 1990. IEEE Transactions on Reliability, 39(4):409-418, Oct 1990.
J. Hudak, B. H. Suh, D. Siewiorek, and Z. Segall. Evaluation and Comparision of fault-tolerant software techniques. IEEE Transactions on Reliability, 42(2), June 1993.
W. Kao, R. Iyer, and D. Tang. FINE: A Fault Injection and Monitoring Environment of Tracing the UNIX System Behavior under Faults . IEEE Transactions on Software Engineering, 19(11):1105-1118, Nov 1993.
A. Kanawati, N. Kanawati, and J. Abraham. FERRARI: A Flexible Software-Based Fault and Error Injection System. IEEE Transactions on Computer, 44(2), Feb 1995.
J. D. Musa, A. Iannino, and K. Okumoto. Software Reliability - Measurement, Prediction, Application. McGraw-Hill Book Company, 1987.
M. Sullivan and R. Chillarege. Software Defects and their Impact on System Availability - A study of Field Failures in Operating Systems. In Digest of Papers The 21st International Symposium on Fault-Tolerant Computing, pages 2-9, 1991.
D. Siewiorek, J. J. Hudak, B. Suh, and Z. Segall. Development of a Benchmark to Measure System Robustness. Digest of Papers The 23rd International Symposium on Fault-Tolerant Computing, pages 88-97, 1993.